

Gemma 4 Lands to Great Reviews
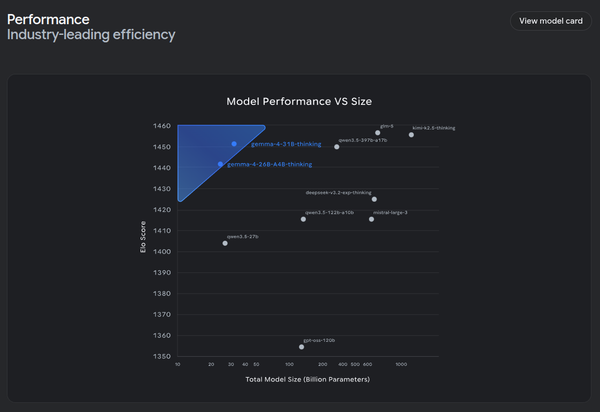
On release, there were a few people suggesting that there was nothing special about Gemma 4. This was missing the point - weight, Gemma 4 outperforms the current landscape of models and has tuning pipelines. This is the true value of Gemma 4.



