
Gemma 4 Lands to Great Reviews
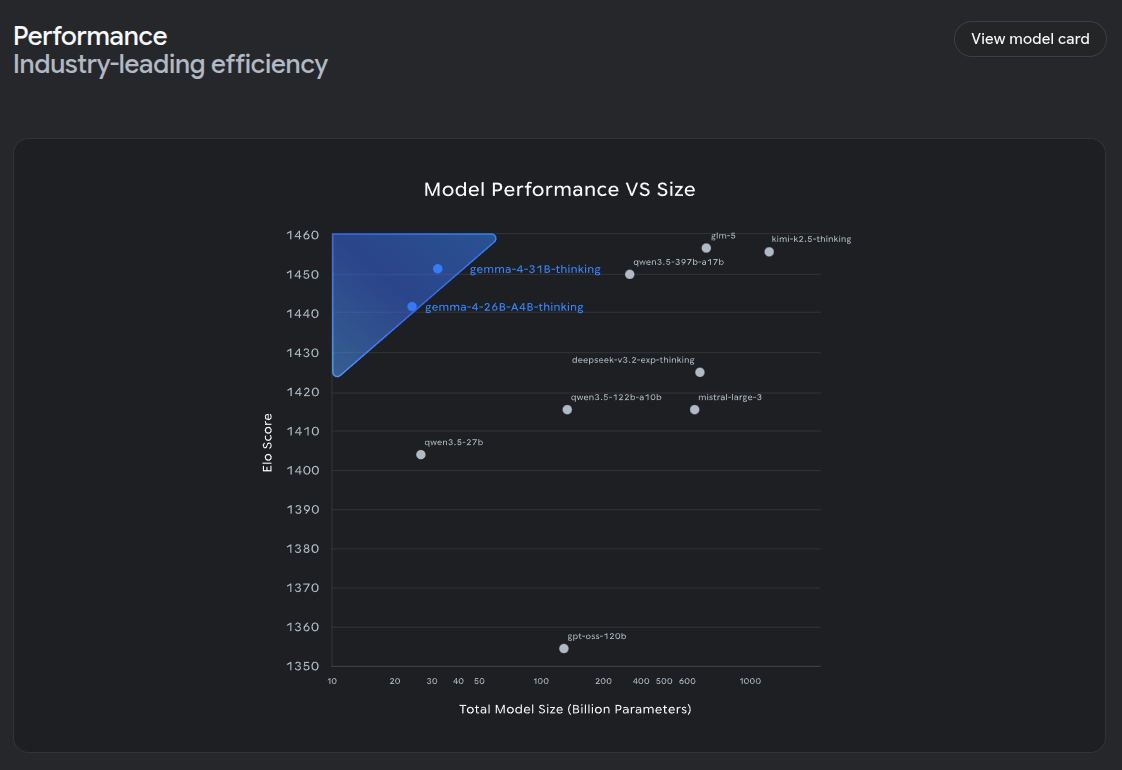
On release, there were a few people suggesting that there was nothing special about Gemma 4. This was missing the point - weight, Gemma 4 outperforms the current landscape of models and has tuning pipelines. This is the true value of Gemma 4.

Punching Above Weight
On release, there were a few people suggesting that there was nothing special about Gemma 4. This was missing the point - weight, Gemma 4 outperforms the current landscape of models and has tuning pipelines. This is the true value of Gemma 4.
Small Weight Models Available
Gemma 4 released with E2B and E4B versions being equivalent to larger parameter models. These are specifically for edge devices and mobile devices.
We are quickly bridging the gap to LLM powered apps rather than chatbots everywhere, and this is the true goal of working with LLMs
The next generation of mobile apps will have the ability to use LLMs to augment answers. Whether that's through natural language querying, voice querying, object identification, or causal generation, the landscape should be more than just chatbots and gemma 4 can help deliver those solutions.
Trainable and Extensible
Similar to other Gemma models (functionGemma, embeddingGemma, shieldGemma, etc) you are able to train these models and customize them for your specific goal.
A YouTube video from Google explains how quickly you can get started.
Fine tuning Gemma in Google Cloud
There are plenty of tutorials on fine-tuning Gemma models available.
Advocating fine-tuning and extending original model functionality is a theme you'll see here on KeySmash.dev in the future.
You can, of course, do similar fine-tuning with models like Qwen but Google has been far ahead of the pack by offering these open weight models with training for quite some time already. The training landscape is mature and a wide variety of businesses have been using Gemma models with these fine-tuned variants.
FunctionGemma specifically deserves a mention. The goal here was to provide a model you could fine tune that would help you to have a portion of your workflow dedicated to early understanding of if a tool or intent needed to be called. For custom tooling or pipelines with consistent interfaces, this would be a faster way to quickly decide on if a tool was needed in the current model workflow.
These types of innovations on small models and spurpose-built models is what makes Gemma unique.
Early Critiques
Over social media, a few users have reported that the 31B variant doesn't perform much better than other models. They seem to be expecting the Gemma 4 series to outperform significantly beyond its weights. While in most cases it does, it is unlikely you're going to see a massive boost in something like coding. The models have limited parameters - the efficiency and performance-by-weight is the true goal here. It is not meant to contend directly with frontier models like Anthropic's Opus or even Google's own Gemini Flash 3.1.
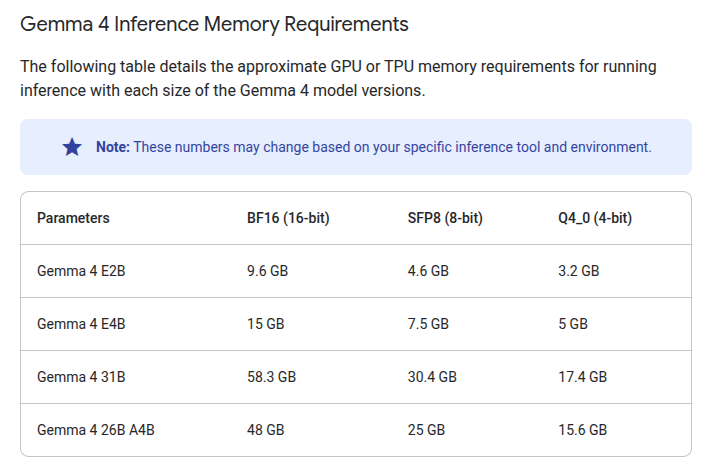
My personal early critique is that they should've tried to manage to cram 26B-A4B Q4 in under 16G of RAM - this is a sweet spot for most gaming desktops and, with a GUI, the current RAM requirement of 15.6G simply will not fit. It would've been really great to have this model on the average consumer "gaming machine".
Final Thoughts
The Gemma 4 models are absolutely state of the art models with the most performance per weight. While users may be disappointed they don't have the raw coding performance of larger models, they may be slightly missing the point. You can extend these models through fine-tuning the entire suite of models.
Stick around for more discussion about models that can run on the edge and on mobile.



